you know what? no intro.
import torch
import torch.nn as nn
from math import tanh
FACTOR = 1.0 - tanh(1.0) # approximately 0.24
class LeakyTanh(nn.Module):
"""canonical version"""
def forward(self, x):
return nn.functional.tanh(x) + FACTOR * x
class TLeakyTanh(nn.Module):
"""alternative trainable version"""
def __init__(self):
super().__init__()
self.factor = nn.Parameter(torch.tensor(0.24))
def forward(self, x):
return nn.functional.tanh(x) + self.factor * xthe three axioms of activation functions
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "NOT RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
- it MUST be nonlinear (because otherwise a multi-layer perceptron collapses down to a one layer perceptron by way of basic matrix multiplication. unless you're tom7).
- it SHOULD NOT have a vanishing gradient (the derivative of the function should not approach zero in either direction, otherwise backpropagation fails to back the propagation by mercy of a multiplication by zero) nor an exploding gradient (approaching infinity).
- it SHOULD be approximately linear around zero and generally within the range [-1, 1] (empirical).
sounds easy, right? nah:
| function | axioms | notes | ||
|---|---|---|---|---|
| 1 | 2 | 3 | ||
| Identity | NO! | YES! | YES! | catastrophic |
| Square | YES! | NO!!!!! | Barely | terrible |
| Square Root | YES! | ?????? | Undefined | REALLY terrible |
| Cube | YES! | NIGHTMARE NIGHTMARE NIGHTMARE |
Fine | Do Not |
| Sigmoid (technically Logistic) | YES! | NO! | NO! | first thing everyone learns. it Barely approximates identity. very bad. use it on the last layer only please. |
| Softmax | what | ? | ?? | ...not an activation function. someone more autistic than me please try this so that i don't have to make leakytanh1.html and start numbering my pages like a zettelkasten |
| LayerNorm | ??? | ????? | ??????? ?????? |
|
| RMSNorm | ||||
| ReLU | YES! | NO! | ...kinda | just works. very computationally efficient! intuitively makes sense (arguably more than sigmoid) |
| LeakyReLU | YES! | ...kinda | ...kinda | often worse than ReLU for reasons beyond comprehension. about as computationally efficient, negligably slower. |
| PReLU | YES! | ...kinda | ...kinda | this is just leakyrelu why is this separate in pytorch docs |
| RReLU | YES! | Probably | uh | why |
| ELU | YES! | ...kinda | YES! | solid |
| GELU | YES! | ...kinda | ...kinda | well well well if it isn't the Transformer activation function |
| SiLU (aka Swish, kinda) | YES! | ...kinda | ...kinda | if you say you use this you don't exist |
| CELU | YES! | ...kinda | yes | |
| SELU | YES! | ...kinda | Sure Does | |
| Mish | YES! | ...kinda | ...kinda | |
| TanH | YES! | NO! | ...kinda | a fucking Meme. if you said this one, you are lying. this is no one's favorite. |
| LeakyTanH | YES! | YES! | YES! | if you said this one, you are correct. this is the best one. |
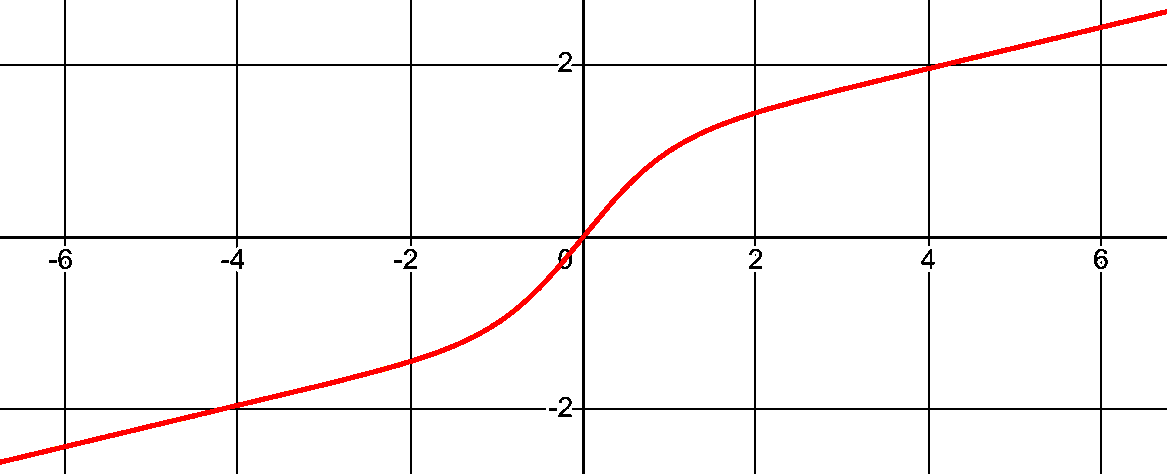
def leakytanh(x):
return tanh(x) + FACTOR * x
assert leakytanh(-1.0) == -1.0
assert leakytanh(0.0) == 0.0
assert leakytanh(1.0) == 1.0
real?
yeag.
...
Okay Fine: it makes narrower, deeper networks train a decent amount more and faster. the nonvanishing gradient lets the gradients propogate without disappearing into nonexistence. i occasionally engage in ai contest shenanigans and sometimes leakytanh is literally the only thing separating me from the person below me.
when should i use it
it is NOT RECOMMENDED use it in a CNN. empirically it's worse than ReLU, for some reason. it is RECOMMENDED to use it in, again, Very Deep Networks (it Partially reduces the need for things like skip connections). you can also sometimes do things like this:
class Residual(nn.Module):
def __init__(self, *subseq):
super().__init__()
self.subseq = nn.Sequential(*subseq)
def forward(self, x):
return self.subseq(x) + x
model = nn.Sequential(
...,
Residual(
nn.Linear(64, 16), LeakyTanh(),
nn.Linear(16, 16), LeakyTanh(),
nn.Linear(16, 16), LeakyTanh(),
nn.Linear(16, 16), LeakyTanh(),
nn.Linear(16, 64)
),
nn.Linear(64, N_CLASSES)
)which can. like. Sometimes be better. i don't know. i'm an ant on the tightrope that is weird cursed ML shit. eat cool fish