
i think talking about kasparov vs deep blue is a bit overdone at this point so i've linked you the wikipedia article if you don't know what it is. it's a bit ironic i'm mentioning it too but oh well
anyways, i've been always fascinated by how game-playing algorithms work, and i recently decided to implement one for the browser. this ended up as probably my first project over a thousand lines of code and after using javascript for so long, i must say camelCase is starting to grow on me. but to explain said algorithm, i think it's more intuitive to go through a similar one
at the core of minimax is the game tree. and what's a game tree? well, heh.
in computer science there is this endlessly useful data structure called a tree.
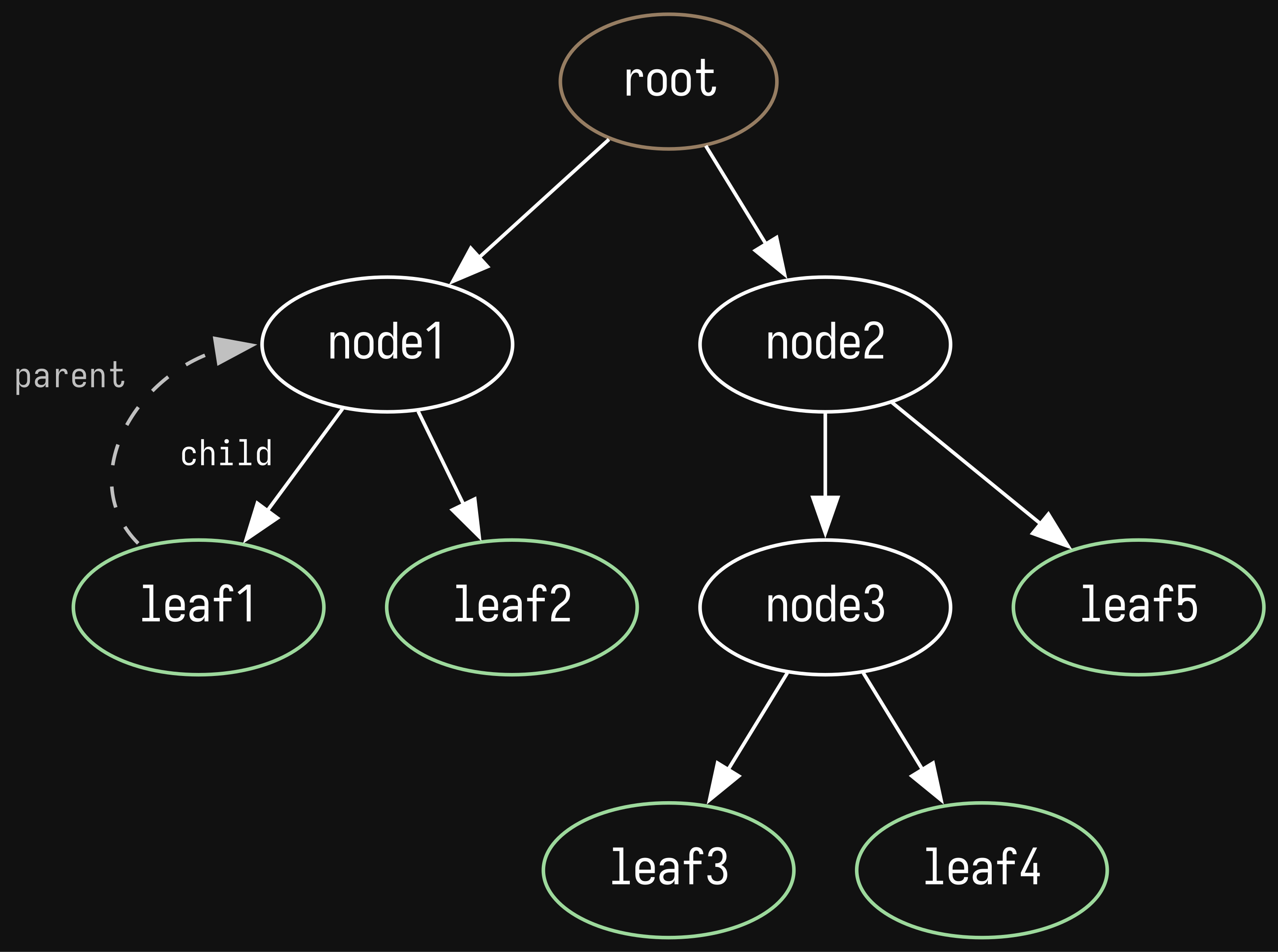
you can think of it as a hierarchy where everything points down, starting from the root node. each node points to its children and the node that pointed to the current one is called the parent. nodes can have only one parent, except for the root, which has none. nodes with no children are called leaves.
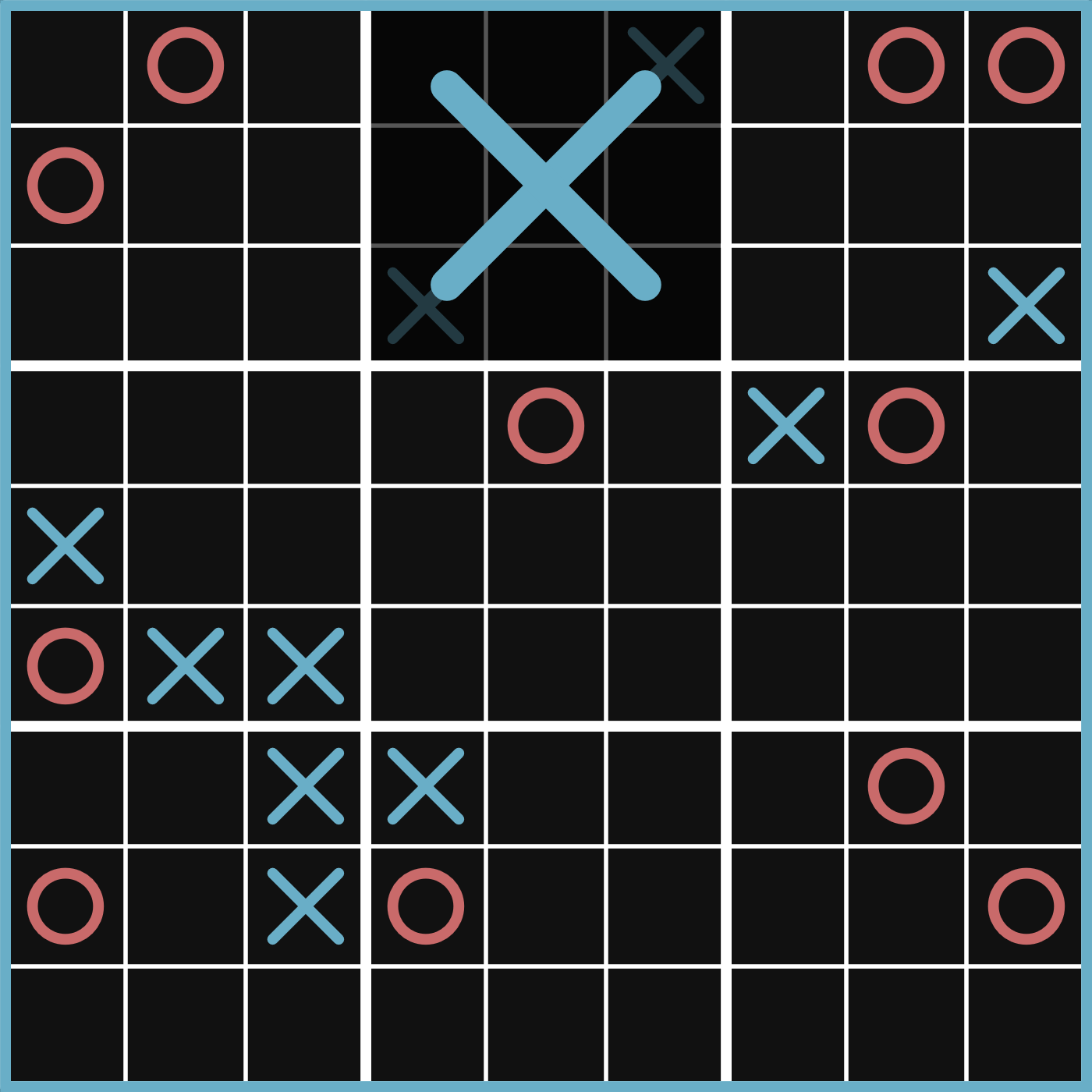
the game tree is just a tree where the root node is the current game state and the children are the states reached after all possible moves are played in the current state. here is an example of a late game tic-tac-toe board:
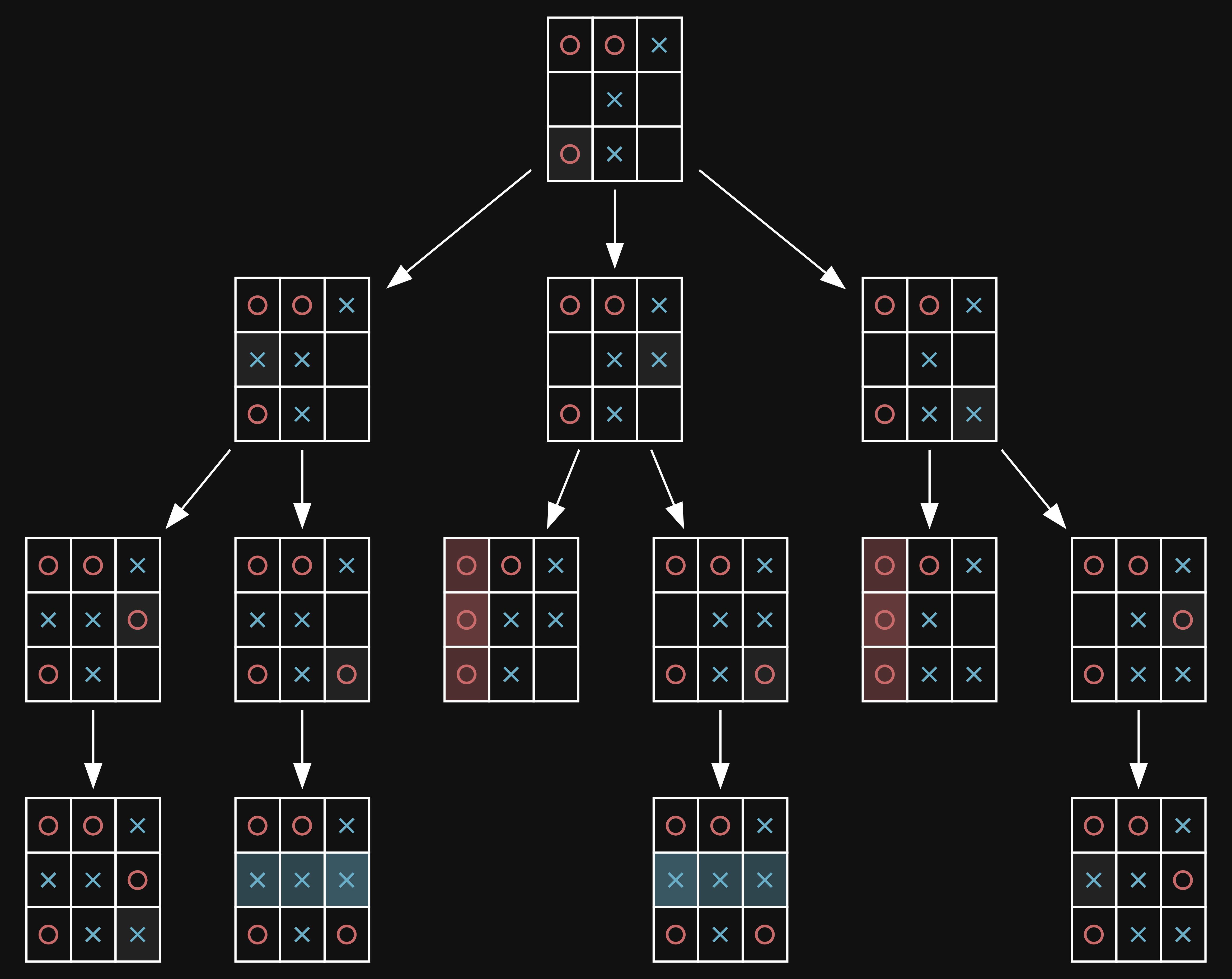
the diagram might be a bit overwhelming at first, but try starting at the root, thinking about what you would play, and "walk" down the tree. you might notice duplicate states, and that's because tic-tac-toe is quite simple and identical states are far more common, the same example for chess would be quite more sophisticated.
now, here is how to play the optimal move using the game tree.
minimax tries to play optimally by assuming its opponent is also playing optimally, effectively trying to play the move that will give its opponent the worst possible choice of moves. the name comes from the fact that the opponent will try to minimize a value that the algorithm will try to maximize.
the game value is just a metric of how good the game is for the player who we are playing as - the higher, the better, hence why we want to maximize it. it can be some score (like in scrabble for instance), but in our case tic-tac-toe has only 3 possible end states - where the player wins (we assign it a value of 1), where there is a tie (0), and where the opponent wins (-1). minimax starts from the bottom up, successively picking moves that minimize the value when it's the opponents turn, and maximizing when it's the player's. when it has computed all of the values, it just picks the child of the root with the maximum value.
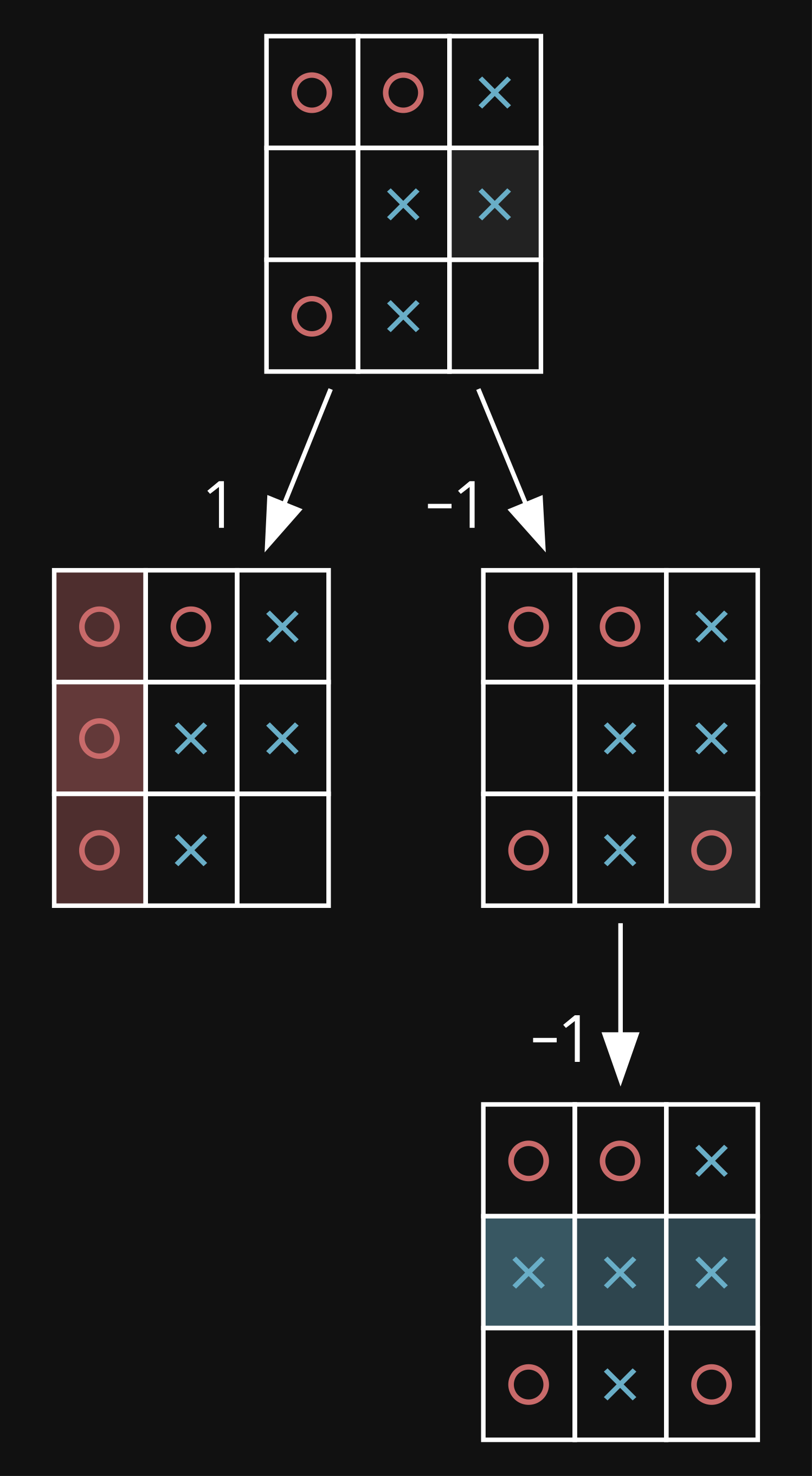
here is an example where it's O's turn. O's win has a value of 1 since we're playing as them, so X's win is assigned a value of -1. then that node's parent is a state where it's X's turn, so it finds the minimum value (its only one value), and sets it as its own. finally, all values are calculated so we pick the root child with the highest value, and that's the left branch, winning us the game. feel free to try this out on the previous diagram to get a bit more of an idea of how this algorithm works (it's X's turn this time).
calculating the optimal move comes at a price though, and as you can probably imagine it's resource requirements x3 just the first move of go has 361 () possible places to place a stone, meaning that by move 2 there are just shy of 130 thousand possible games (), making it impossible to search the whole game tree. a way to get around this is just to guess the value with something called a value function (of course sacrificing being optimal). the value function takes in a game state and returns a value, which can be even fractional in our case. for example 0.9 means that it's pretty certain the player will win, while -0.2 means that the opponent has a very slight advantage.
there are a few ways to make a value function, one of them being using a combination of so-called heuristics. an example heuristic for tic-tac-toe is that having two occupied spaces and an empty one on a row, column or diagonal is favourable. there is still a lot of research into hand-crafted evaluation functions, if you're interested, you can find a lot for chess here on the chess programming wiki. anyway, this is actually the reason i didn't implement minimax. i prefer the elegance of purely evaluating from board end states, without having to come up and test different heuristics. this other algorithm is another solution to the problem of having to compute a huge game tree, using a simple trick -
randomness. this algorithm uses the unsurprisingly called monte carlo method. named after the monte carlo casino in monaco, it employs random sampling to converge on a value with an acceptable error bound. an example is flipping a coin over and over to calculate the probability of it landing on heads. at first the calculated probability will be inaccurate, but after many flips you'd expect it to be roughly 50%. this is the so-called law of large numbers, where after many independent samples, the average gets closer and closer to the real value. another example is how at a casino the house may have a 0.2% higher chance of winning, but after sufficiently many games, that's still a guaranteed profit.
monte carlo tree search uses random sampling to approximate the minimax game tree (even though it only converges to it in "monte carlo perfect" games, which require random turn order). a perk of this, is that you can stop the search at any time, but of course leaving it running for longer gives better results. mcts works in discrete steps called rounds (or iterations), each round consisting of 4 phases. to illustrate the algorithm, i will be abstracting the game state to ( as in index). it can be literally anything - tic-tac-toe, chess, go, all the concepts will still apply. let's start with just the root node, and you'll notice that we've given it some values, which will talk about at the end

we start at the root, progressively choosing the node with the highest ucb score. i'll explain how ucb is calculated later, since now there is only one node to pick, so we choose the root.
here we just take the selected node and create children for all resulting states from all possible moves at our current node. let's say there are two possible moves at the root node and we expand it:
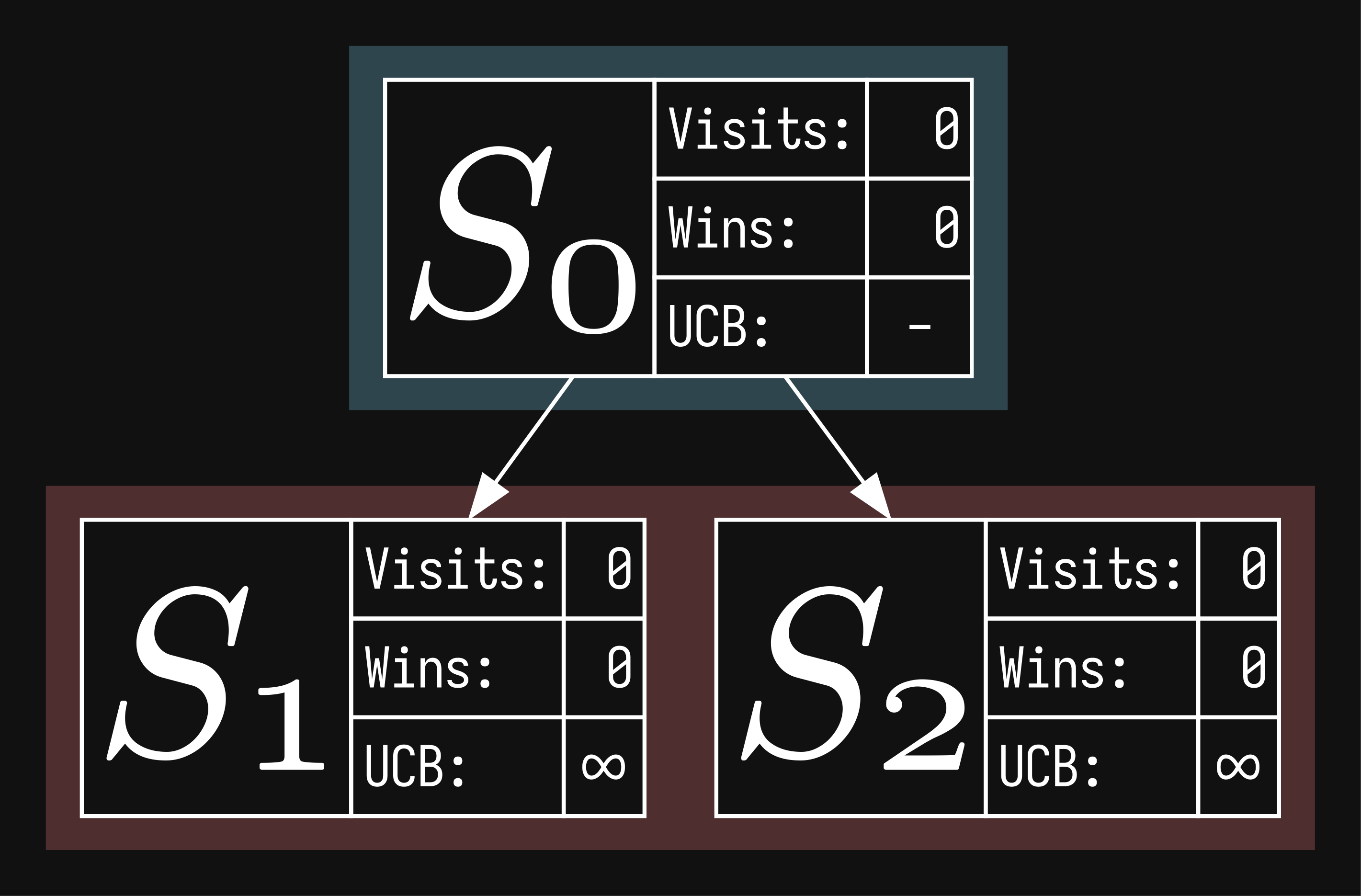
also, i've now colored the nodes assuming it's a two player game. it helps with visualizing which nodes will get updated in phase 4.
here is where we employ the monte carlo method. we select a random child from the expansion (lets say ) and play a game, choosing random moves until an end state is reached. in mcts, this is called a rollout. we play a random game and
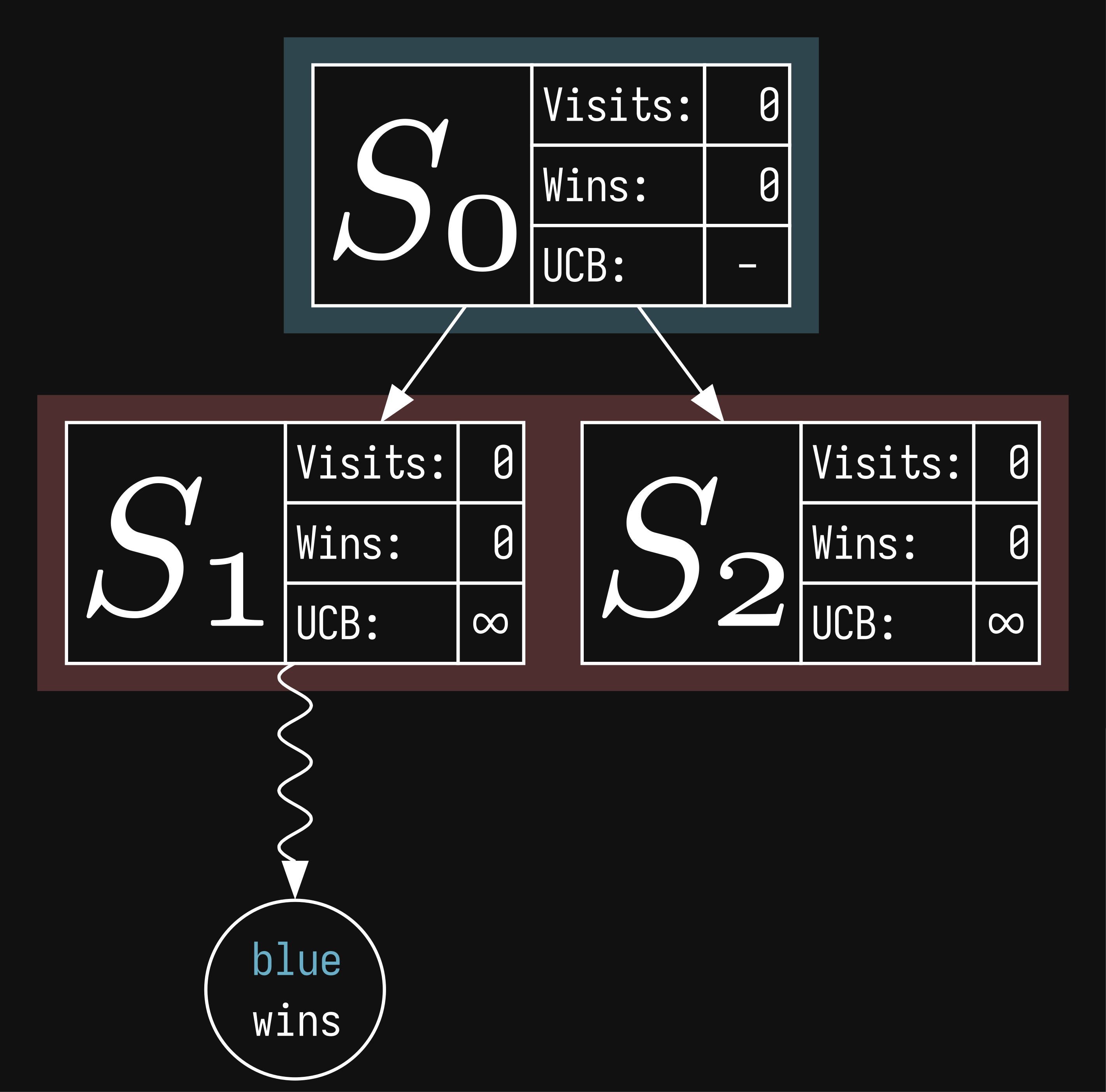
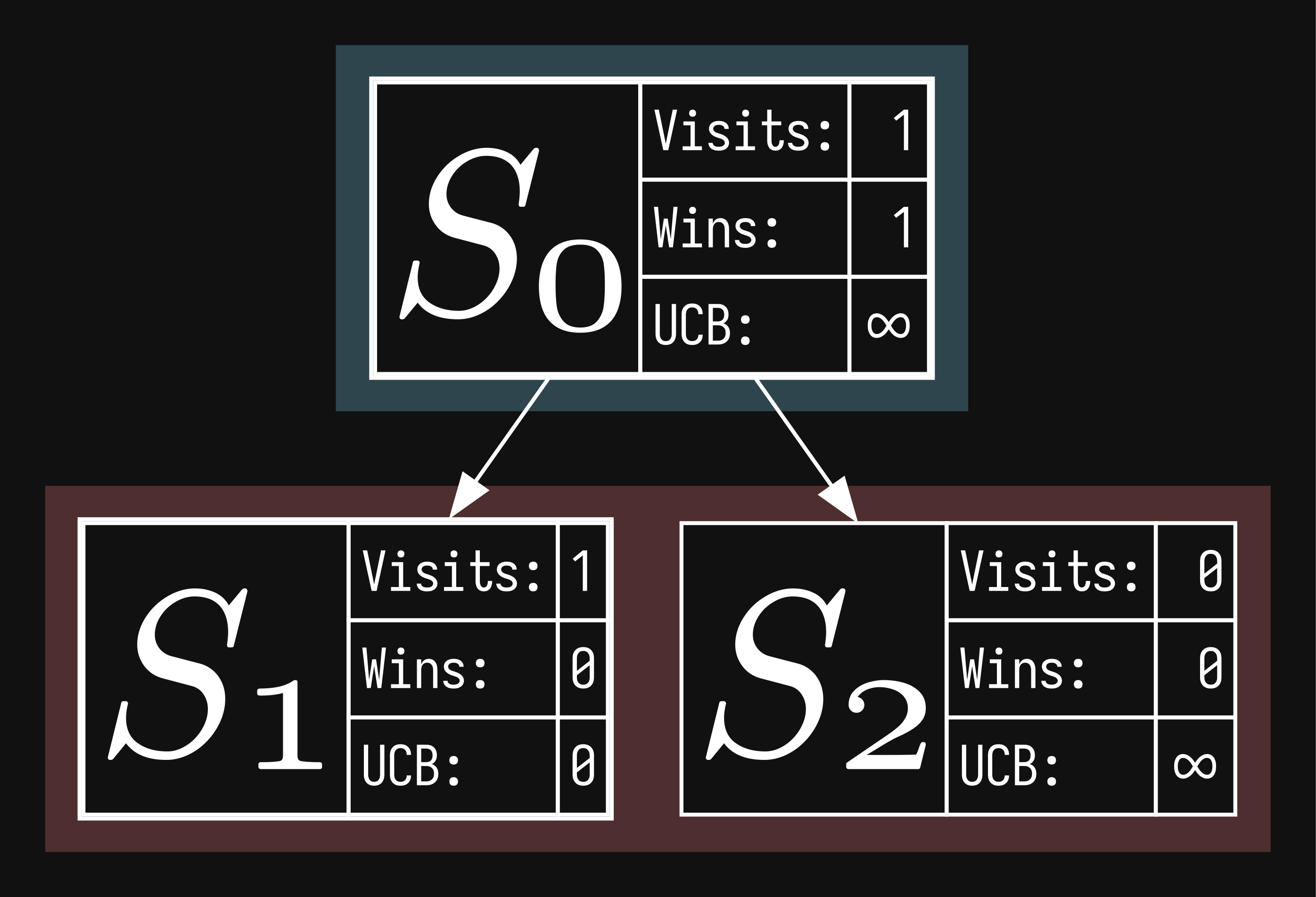
we start from our node, and successively get the parent (walk up the tree) until we reach the root. for each node we reach, we increment the visits and then increment the wins only if the winner just played at that node. hence in this example, even if it's the red player's turn at , it's going to be updated because blue just played. if you think back to minimax, when we're at a node that's our turn, we want to choose the move that maximizes our score. in this way, we'll let the algorithm calculate the win rate correctly as you'll see in the following step. in this example, only the root node gets a win. ties actually also work in the same way, just adding only 0.5 instead. this incentivizes our bot to prolong games, even if it knows it's going to lose. and now the final third value, ucb:
ucb is actually calculated at the selection phase, but now that you know the algorithm, it's easier explaining it. it tries to tackle a main problem in many areas of research, called the exploration-exploitation dilemma - we need to explore the feasibility of good moves that we already know (exploitation), but we also have to choose new moves which might turn out to be even better (exploration) there are actually a few versions of ucb, the one that is commonly used is ucb1, which is the following formula
where is the number of wins at the current node, is the number of visits at the current node, and is the number of visits that the parent of the node has. the first component is the exploitation term - it's just the win rate, good moves have higher win rates, so we'd like to develop them, the other component, the exploration term is a bit more complicated. the main intuition behind it is that increases as the node's siblings (other children of the parent) get visited. the rest is derived from the multi-armed bandit problem. the last part is , the exploration parameter, which is a constant controlling the balance between exploration and exploitation. in theory it's , but in practice it's tuned. now we can update all the values in the tree:
finally, let's start a new round. we walk down the tree, select the node with the highest ucb (now ) and expand it. there is one possible move, which we do a simulation from and let's say red wins this time. we update backpropagate leaving us this board state:
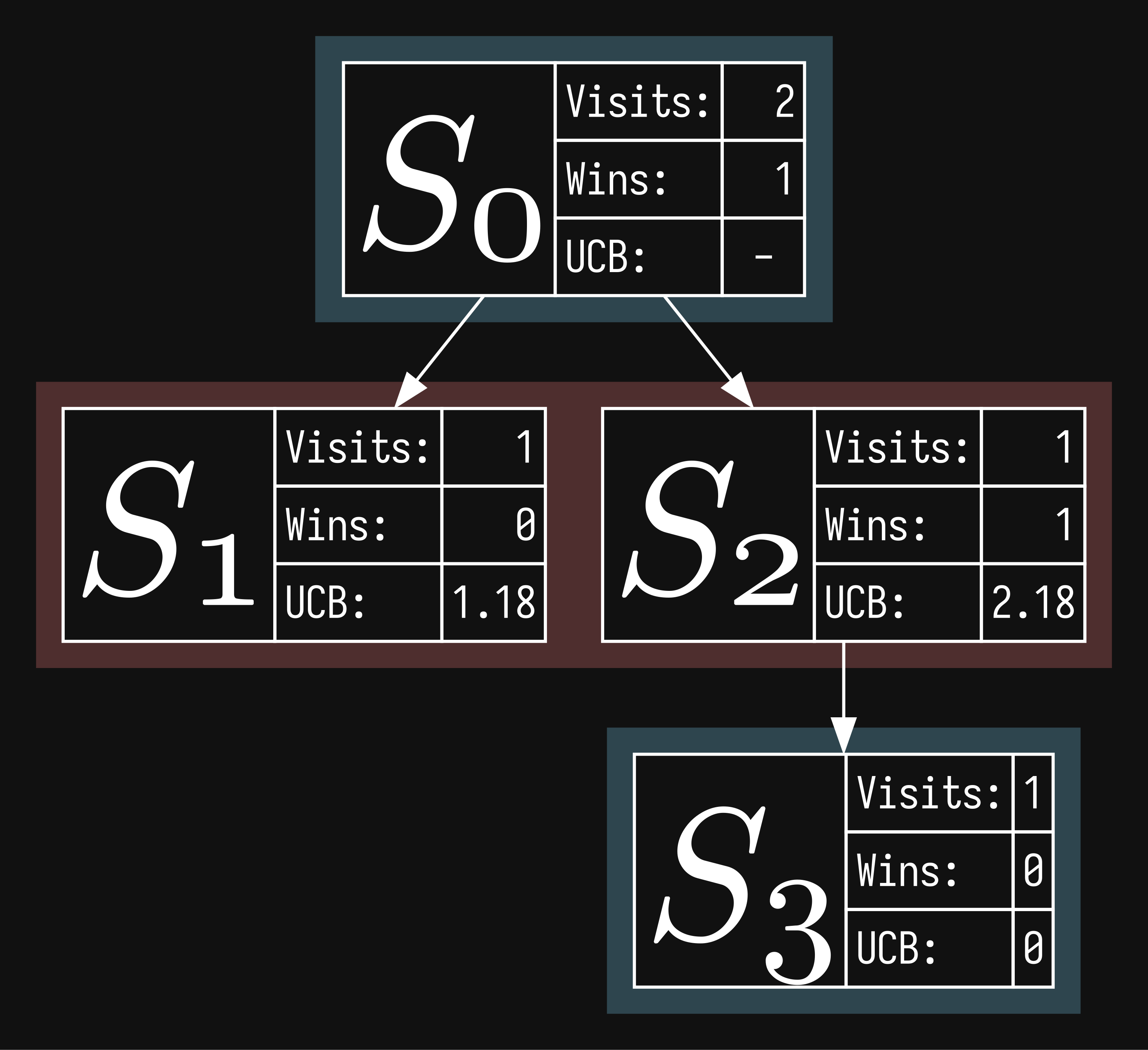
you can see how the exploitation term is winning out on the first row, because both nodes are equally explored. on the next round will be selected, then and expanded, then simulated, on and on and until we decide to stop (usually after a set time). for instance, here's our original game tree but with 30 rounds of mcts ran on it
to play a move, we actually choose the game state with the most visits, not the highest winrate or ucb. the ucb has an extra exploration term, which artificially boosts scores for unexplored nodes, while the winrate is prone to error, especially if unexplored. the visit count is a natural choice, since it's the most explored node and ucb gravitates towards nodes with high winrates. and that's monte carlo tree search!
i decided that i wanted to make this project interactive, so i tried my hand at p5.js, a browser version of processing. it's basically a layer of abstraction above javascript canvas, which saved me a good amount of headaches. for the game, i chose
or "ultimate tic-tac-toe", which seems to be the more common name but i think this one is cooler. i saw a classmate playing this once which is what inspired me to do this whole thing. it's just difficult enough that i can't just brute force all positions, but just easy enough that i don't have to worry about complex game states or the game tree growing too fast. the rules are the following:

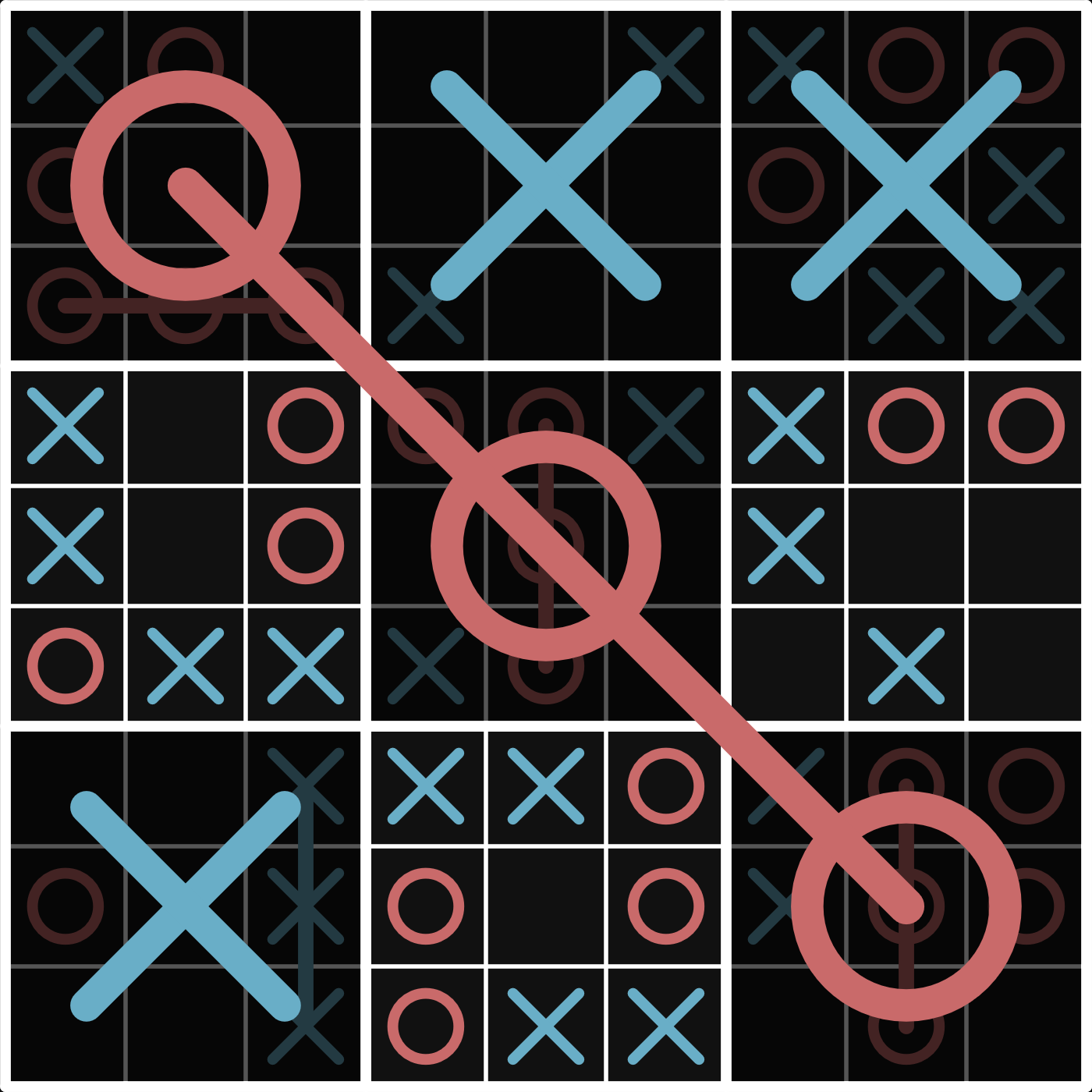
this game is surprisingly strategic, and in my experience playing it, at some point just turns into players forcing each other into zugzwangs and just like tic-tac-toe, it's also playable on paper.
as far as the X advantage goes, i ran 6.3 million random games, with X winning about 41.15% of games, O winning 36.61% of games, and a tie happening 22.24% of the time, meaning that X does have a 4.5% advantage, but that's also much better than tic-tac-toe, with its probabilities being 58.49%, 28.81%, and 12.7% respectively (that's a 30% edge!)
i decided to add a purely random bot and 3 difficulties. i settled on time limits of 100ms, 1s, and 5s respectively for them. i've also added an early stopping feature, based on this paper, which introduced the STOP method. in essence, we stop searching for games when even if at this point in the search we started only visiting the second best move, by the end the most visited move will remain the same.
i've also added an eval graph, where we run mcts for some time and track the frequency of the 3 end game states and calculate a final eval score by getting the difference in percentages that X and O win. you can imagine it as something like , where are the number of wins of the respective player recorded over - the number of rounds ran. as X gets a higher chance of winning, the eval leans toward 1, and as O gets more wins it leands toward -1. an eval score of 0 means that neither player has an advantage and draws aren't in this calculation for the exact same reason, they benefit both players an equal amount.
i've chosen 500ms as a time not too fast so that the algorithm doesn't catch major lines of play, but not as slow as to take forever to eval a whole game. this means that the medium and hard bots technically have a more correct internal evaluation, which is why i include them in the logs (note: it's relative though so positive just means good for the current player). the eval board is mostly made for human vs human play, but it's interesting to see the general tendencies of matches with bots.
another thing that i thought would be neat to add is a realtime heatmap of the most visited nodes, though you can only see it with the medium and hard bots.
you can find it here as a standalone webpage, and you can show/hide the eval board and debug console by changing the url parameters
variants of mcts are a dime a dozen. a main one that actually applies both to mcts and minimax is that you can actually reuse the game tree. since every turn just ends up going down the same game tree, you can use previous computation to play even better moves.
and to circle back to the game of go, you might probably know of alphago, the first computer program to get good enough to beat a grandmaster. it uses a version of uct (ucb applied to trees, this is technically what the method used in the selection phase is called, since there are other selection methods), which called puct (predictor + uct), where a few neural networks are used as a value function to strengthen mcts even further. one thing about alphago vs lee sedol though is that the deepmind team reportedly used 1920 cpus and 280 gpus, plus all the compute they needed to actually train the model.
this turned out far more rambly than i expected, so if you managed to understand any of this, congrats!! ;w; you can find the source code here, but again don't really expect anything please. i've tried my best, but the new game button still has some bugs
while writing this, i learned that the monte carlo method is actually separate from monte carlo algorithms (and also las vegas algorithms). also, researching other peoples' implementations of the idea that i had, i discovered an alphazero-like program for playing ultimate tic-tac-toe here that also runs in the browser! and as far as i have found, this is the current strongest bot.
© by nicole, licenced under CC BY-SA 4.0; go back